


On Wednesday 17th February 2021 the ESCAPE consortium held the “Enhancing science through sharing software - benefits & use cases” webinar with the aim to share the ESCAPE Open source Scientific Software and Service Repository latest development status, best practices and use cases on how to enhance scientific discoveries by sharing software and fostering software co-development. The webinar gathered 62 registrants, 88% of which coming from an Academia/research background.
After giving a general overview of the ESCAPE project and its relation with the European Open Science Cloud, Kay Graf, the ESCAPE OSSR WP3 leader, explained how ESCAPE is working to make software and derivatives of software openly available based on the FAIR principles to foster and enable open science, software interoperability and re-use, federation of available software resources and cross fertilisation between the European Strategy Forum on Research Infrastructures (ESFRIs) and beyond.
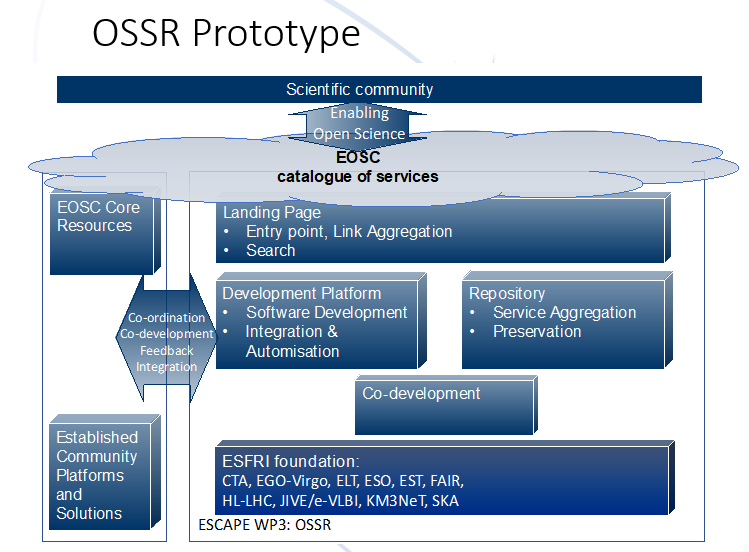
Figure 1 – ESCAPE OSSR prototype
Kay then shared how to improve the ESCAPE OSSR onboarding process. There is constant coordination between the EOSC core, established community platforms and solutions and the ESCE OSSR, consisting of a landing page, a development platform (GitLab instance) and a repository (Zenodo).
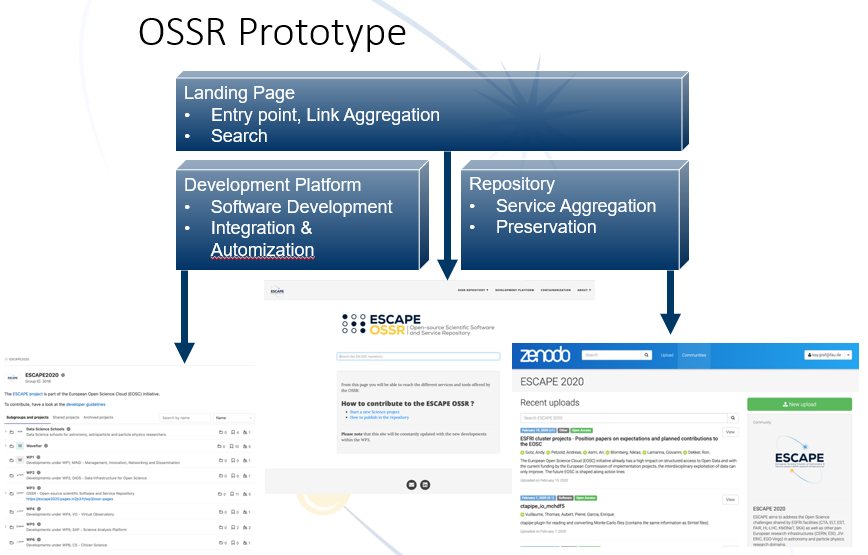
Figure 2 – ESCAPE OSSR development platform and repository
During the presentation, the “Crab bundle” was introduced as an example of open science. The crab bundle use case is an example of an open science project using already available open data to perform a re-analysis, which has been made available on the Zenodo public repository. This use case has been made possible thanks to an infrastructure and services that host FAIR contributions:
There are already some use case projects developed under ESCAPE using the Open Source Scientific and Software Repository, such as:
The fully documented source code of these onboarded ESCAPE OSSR use cases can be found in the OSSR Zenodo repository with an open license that will allow other researchers to use and modify them for their own purposes.
The Square Kilometre Array has designed data challenges to represent the workflow of users interacting with their data products to help promote software development workflow best practices regarding:
Promoting full replication of code and data is the gold standard in any scientific data analysis, as a way to simplify scientific discoveries.
Without this replicability, scientists will have to go through extensive effort to replicate certain results from a specific dataset, which is a clear obstacle for open science scientific innovation.
On the other hand, promoting replicability best practices, such as sharing containers with versioned data, allows other researchers to quickly replicate any research results and potentially spark new scientific breakthroughs.
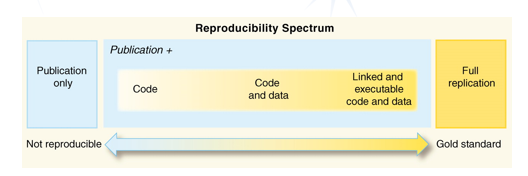
Figure 3 - Peng 2011 (https://doi.org/10.1126/science.1213847)
(and Rachael Ainsworth, https://github.com/rainsworth/osip2019-containerisation-workshop)
Given the growing amount of data produced by recent researchers, such as SKA’s researchers, it is extremely important to apply replicability best practices to any scientific analysis made with such data, for the benefit of all researchers and society at large.
Astro and particle physics experiments are producing an incredible and increasing amount of data, which is making it difficult for researchers to easily access data archives, label objects in an astrophysical catalog and classify noise or signal sources without human intervention. Before the amount of data becomes too big to be managed by current algorithms, it is critical to develop new workflows for data analysis. The ESCAPE partners, namely KM3NeT-ORCA/ARCA, the Square Kilometre Array and the Cherenkov Telescope Array are already implementing such innovative workflows using machine learning to help them navigate the growing amount of data produced.
The webinar ended with Kay Graf sharing a sneak peek into the future of the ESCAPE OSSR service. The ESCAPE team is expected to finalise the OSSR service prototype implementation to foster software co-development, re-use and innovation and create its full integration into the EOSC Portal by August 2022.